Prueba de hipótesis para diferencia de proporciones $p_1 - p_2$
Sean $X_{1,1}, X_{1,2}, \ldots, X_{1,n_1}$ y
$X_{2,1}, X_{2,2}, \ldots, X_{2,n_1}$ dos muestras aleatorias iid de
tamaño $n_1$ y $n_2$, tal que $X_{i}\sim b(n_i,p_i)$, para
$i=1,2$, entonces si $n_1$ y $n_2$ son suficientemente grandes tal
que $n_1, n_2\geq30$, y si las proporciones desconocidas $p_1$ y
$p_2$ no se encuentran cercanas a $0$ o $1$, tal que $n_ip_i>5$
y $n_i(1-p_i)>5$, para $i=1,2$, entonces un una prueba de hipótesis
para la diferencia de las proporciones $p_1-p_2$ será de la forma

Ejercicio
Una empresa de computación decide realizar un cambio en el proceso de
fabricación de uno de los componentes que requiere en sus portátiles, y
está en interesado en saber si dicho cambio ofrece una mejora
significativa en la rendimiento que sus equipos ofrecen.
Para
determinar si el cambio en el proceso de fabricación mejora el
rendimiento que sus equipos ofrecen, deciden tomar una muestra de
equipos antes y después de la implementación del nuevo proceso de
fabricación y se evalúa la velocidad de procesamiento para la ejecución
de un programa determinado. Suponga que se encuentra que \(120\) de
\(500\) computadores fabricados con el método actual ofrece un
rendimiento superior al promedio, mientras que, \(220\) de \(700\)
computadores fabricados con el nuevo método ofrece un rendimiento
superior al promedio.
Basados en la información obtenida,
emplee un nivel de confianza del \(2\%\) para probar si la proporción de
nuevos equipos que ofrecen un rendimiento superior al promedio, es igual
o superior a la proporción de equipos actuales que ofrecen un
rendimiento superior al promedio.
Solución
Como estamos interesado en comparar la proporción de rendimiento
superior al promedio entre los nuevos equipos y los actuales, para saber
si los nuevos equipo son iguales o superiores a los actuales, tendremos
que la hipótesis de interés está dada por \[\begin{align*}
H_0:p_N - p_A \geq 0\\
H_1:p_N - p_A < 0
\end{align*}\]
Entonces como estamos interesados en hacer inferencia sobre una
diferencia de proporciones, y nos encontramos frente a una hipótesis
unilateral, tendremos que estamos ante la siguiente situación
 En donde se observa que el estadístico de prueba está dado por
\[\begin{align*}
Z_c = \frac{(\hat{p}_N - \hat{p}_A) - d_0}{\sqrt{\frac{p^*(1-p^*)}{n_N} + \frac{p^*(1-p^*)}{n_A}}} \stackrel{a}{\sim} N(0,1)
\end{align*}\]
De lo anterior se observa que para el cálculo se requiere de las
proporciones muestrales \(\hat{p}_{N}\) y \(\hat{p}_{A}\), y
proporciones conjuntas \(p^*\), las cuales se pueden obtener a partir
del tamaño de muestra y del número de éxitos obtenidos, tal que para el
caso de los equipos construidos con el nuevos procedimiento se tendrá
que \[\begin{align*}
\hat{p}_N &= \frac{\text{# de equipos nuevos con rendimiento superior}}{\text{Total equipos nuevos evaluados}} \\
&= \frac{x_N}{n_N} \\
&= \frac{220}{700} \\
&= 0.3142857
\end{align*}\]
mientras que para los equipos que se construyen con el procedimiento
actual, se tendrá que
\[\begin{align*}
\hat{p}_A &= \frac{\text{# de equipos actuales con rendimiento superior}}{\text{Total equipos actuales evaluados}} \\
&= \frac{x_A}{n_A} \\
&= \frac{120}{500} \\
&= 0.24
\end{align*}\]
Ahora, la proporción conjunta es igual a \[\begin{align*}
p^* &= \frac{x_N + x_A}{n_N + n_A} \\
&= \frac{220 + 120}{700 + 500} \\
&= 0.2833333
\end{align*}\]
Una vez calculados todos los valores asociados al estadístico de prueba,
se procede a su cálculo, el cual está dado por \[\begin{align*}
Z_c &= \frac{(0.3142857 - 0.24) - d_0}{\sqrt{\frac{0.2833333(1-0.2833333)}{700} + \frac{0.2833333(1-0.2833333)}{500}}} \\
&= 2.815407
\end{align*}\]
Ahora, con el fin de decidir si el estadístico de prueba apoya o no la
hipótesis establecida, se emplea en esta ocasión la región crítica la
cual estará dada por \[\begin{align*}
RC:\{Z|Z<-Z_{\alpha}\}
\end{align*}\]
en donde el valor crítico \(Z_{\alpha=0.02}=2.053749\) y por tanto la
región crítica será \[\begin{align*}
RC:\{Z|Z<-2.053749\}
\end{align*}\]
Entonces como el estadístico de prueba no cae dentro de la región
crítica, no hay evidencia significativa en contra de la hipótesis nula,
y por tanto se tendrá que la proporción de nuevos equipos que ofrecen un
rendimiento superior al promedio no es inferior a la proporción de
equipos fabricados con el actual proceso que ofrecen rendimientos
superiores al promedio.
En donde se observa que el estadístico de prueba está dado por
\[\begin{align*}
Z_c = \frac{(\hat{p}_N - \hat{p}_A) - d_0}{\sqrt{\frac{p^*(1-p^*)}{n_N} + \frac{p^*(1-p^*)}{n_A}}} \stackrel{a}{\sim} N(0,1)
\end{align*}\]
De lo anterior se observa que para el cálculo se requiere de las
proporciones muestrales \(\hat{p}_{N}\) y \(\hat{p}_{A}\), y
proporciones conjuntas \(p^*\), las cuales se pueden obtener a partir
del tamaño de muestra y del número de éxitos obtenidos, tal que para el
caso de los equipos construidos con el nuevos procedimiento se tendrá
que \[\begin{align*}
\hat{p}_N &= \frac{\text{# de equipos nuevos con rendimiento superior}}{\text{Total equipos nuevos evaluados}} \\
&= \frac{x_N}{n_N} \\
&= \frac{220}{700} \\
&= 0.3142857
\end{align*}\]
mientras que para los equipos que se construyen con el procedimiento
actual, se tendrá que
\[\begin{align*}
\hat{p}_A &= \frac{\text{# de equipos actuales con rendimiento superior}}{\text{Total equipos actuales evaluados}} \\
&= \frac{x_A}{n_A} \\
&= \frac{120}{500} \\
&= 0.24
\end{align*}\]
Ahora, la proporción conjunta es igual a \[\begin{align*}
p^* &= \frac{x_N + x_A}{n_N + n_A} \\
&= \frac{220 + 120}{700 + 500} \\
&= 0.2833333
\end{align*}\]
Una vez calculados todos los valores asociados al estadístico de prueba,
se procede a su cálculo, el cual está dado por \[\begin{align*}
Z_c &= \frac{(0.3142857 - 0.24) - d_0}{\sqrt{\frac{0.2833333(1-0.2833333)}{700} + \frac{0.2833333(1-0.2833333)}{500}}} \\
&= 2.815407
\end{align*}\]
Ahora, con el fin de decidir si el estadístico de prueba apoya o no la
hipótesis establecida, se emplea en esta ocasión la región crítica la
cual estará dada por \[\begin{align*}
RC:\{Z|Z<-Z_{\alpha}\}
\end{align*}\]
en donde el valor crítico \(Z_{\alpha=0.02}=2.053749\) y por tanto la
región crítica será \[\begin{align*}
RC:\{Z|Z<-2.053749\}
\end{align*}\]
Entonces como el estadístico de prueba no cae dentro de la región
crítica, no hay evidencia significativa en contra de la hipótesis nula,
y por tanto se tendrá que la proporción de nuevos equipos que ofrecen un
rendimiento superior al promedio no es inferior a la proporción de
equipos fabricados con el actual proceso que ofrecen rendimientos
superiores al promedio.
Prueba de hipótesis para una varianza $\sigma^2$
Sea $X_{1}, X_{2}, \ldots, X_{n}$ una muestra aleatoria de una
población normal de tamaño $n$ conmedias $\mathbb{E}(X)=\mu$ y
varianza desconocidas $Var(X)=\sigma_1^2<\infty$, entonces un
contraste de hipótesis para la varianza real $\sigma^2$, a un nivel de
significancia $\alpha$ será de la forma

Ejercicio
Suponga que se realiza un estudio sobre los costos que han tenido proyectos de renovación de parques en la ciudad de Medellín, encontrando que los costos asociados a \(20\) proyectos que se han a cabo en le ciudad, en millones de pesos, fueron de
| 1780 | 2933 | 1220 | 1278 | 1170 | 1032 | 1245 | 2070 | 2040 | 1289 |
| 1531 | 980 | 1730 | 1380 | 2243 | 1687 | 1422 | 1731 | 1435 | 2080 |
Si es posible supone que el costo de construir cualquier parque se distribuyen aproximadamente normal, emplee un nivel de significancia del \(5\%\) para observar si la variabilidad de los costos de cualquier construcción es de al menos \(300000\) millones de pesos\(^2\).
Solución
Como estamos interesados en este punto de observar si la variabilidad de
los costos de cualquier construcción es de al menos \(300000\) millones
de pesos\(^2\) y por tanto la hipótesis de interés está dada por
\[\begin{align*}
H_0:\sigma^2 \geq 300000\\
H_1:\sigma^2 < 300000
\end{align*}\]
En donde, se evidencia que en este caso estaremos bajo la siguiente
situación
 la cual muestra que el estadístico de prueba en esta ocasión está dada
por \[\begin{align*}
\chi^2_c = \frac{(n-1)S^2}{\sigma^2_0} \sim \chi^2_{n-1}
\end{align*}\]
De lo anterior, se observa que para el cálculo del estadístico de
prueba, se requiere de la varianza muestral \(S^2 = 230541.2\), el
tamaño de muestra \(n=20\) y el valor de la hipótesis nula, en donde, al
reemplazar dichos valores en el estadístico de prueba se tendrá que
\[\begin{align*}
\chi^2_c &= \frac{(20-1)230541.2}{300000} \\
&= 14.60094
\end{align*}\]
en donde, al estar frente a una situación unilateral izquierda, se
tendrá que el P-valor para este caso está dado por \[\begin{align*}
P-valor &= \mathbb{P}(\chi^2_{n-1}<\chi^2_c) \\
&= 0.216856934
\end{align*}\]
Entonces, como el P-valor obtenido es superior al nivel de significancia
preestablecido del \(5\%\), se concluye que no hay evidencia suficiente
para rechazar la hipótesis nula, y por tanto, se tendrá que la
variabilidad de los costos de cualquier construcción es de al menos
\(300000\) millones de pesos\(^2\).
la cual muestra que el estadístico de prueba en esta ocasión está dada
por \[\begin{align*}
\chi^2_c = \frac{(n-1)S^2}{\sigma^2_0} \sim \chi^2_{n-1}
\end{align*}\]
De lo anterior, se observa que para el cálculo del estadístico de
prueba, se requiere de la varianza muestral \(S^2 = 230541.2\), el
tamaño de muestra \(n=20\) y el valor de la hipótesis nula, en donde, al
reemplazar dichos valores en el estadístico de prueba se tendrá que
\[\begin{align*}
\chi^2_c &= \frac{(20-1)230541.2}{300000} \\
&= 14.60094
\end{align*}\]
en donde, al estar frente a una situación unilateral izquierda, se
tendrá que el P-valor para este caso está dado por \[\begin{align*}
P-valor &= \mathbb{P}(\chi^2_{n-1}<\chi^2_c) \\
&= 0.216856934
\end{align*}\]
Entonces, como el P-valor obtenido es superior al nivel de significancia
preestablecido del \(5\%\), se concluye que no hay evidencia suficiente
para rechazar la hipótesis nula, y por tanto, se tendrá que la
variabilidad de los costos de cualquier construcción es de al menos
\(300000\) millones de pesos\(^2\).
Prueba de hipótesis para cociente de varianzas $\sigma^2_1/\sigma^2_2$
Sea $X_{1,1}, X_{1,2}, \ldots, X_{1,n_1}$ y
$X_{2,1}, X_{2,2}, \ldots, X_{2,n_1}$ dos muestras aleatorias normales
de tamaños $n_1$, y $n_2$ con medias $\mathbb{E}(X_{1})=\mu_1$ y
$\mathbb{E}(X_{2})=\mu_2$, y varianzas desconocidas
$Var(X_{1})=\sigma_1^2<\infty$ y $Var(X_{2})=\sigma^2_2<\infty$,
respectivamente, entonces un contraste de hipótesis para el cociente de
varianzas $\sigma^2_1/\sigma^2_2$, a un nivel de significancia
$\alpha$ será de la forma

Ejercicio
Se aplican pruebas a \(10\) cables conductores soldados a un dispositivo semiconductor con el fin de determinar su resistencia a la tracción. Las pruebas demostraron que para romper la unión se requiere las libras de fuerza que se listan a continuación.
| Sin Encapsulado | 19.8 | 12.7 | 13.2 | 16.9 | 10.6 | 18.8 | 11.1 | 14.3 | 17.0 | 12.5 |
Otra conjunto de \(8\) cables conductores que forman otro dispositivo, se encapsulan y se prueban para determinar si el encapsulado aumenta la resistencia a la tracción, obteniendo para este caso se requirieron las siguientes libras de fuerza para romper la unión
| Con Encapsulado | 24.9 | 22.9 | 23.6 | 22.1 | 20.3 | 21.6 | 21.9 | 22.5 |
Si se supone que las resistencias a la tracción se distribuyen normalmente, pruebe con un nivel de significancia del \(10%\) su la variabilidad de los cables sin encapsulado es menor a la variabilidad de los cables con encapsulado.?
Solución
En este punto estamos interesados en probar si la variabilidad que
tienen los cables sin encapsulado es menor a la variabilidad de los
cables con encapsulado, y por tanto, tendremos que probar la siguiente
hipótesis \[\begin{align*}
H_0:\sigma^2_{S} \geq \sigma^2_{C} &=> H_0:\frac{\sigma^2_{S}}{\sigma^2_{C}} \geq 1\\
H_1:\sigma^2_{S} < \sigma^2_{C} &=> H_1:\frac{\sigma^2_{S}}{\sigma^2_{C}} < 1
\end{align*}\]
Entonces como el interés es probar que una de las varianzas sea mayor a
la otra, significa que estaremos bajo la siguientes situación
 en donde se aprecia que el estadístico de prueba para esta ocasión
estará dado por \[\begin{align*}
F_c=\frac{S^2_{S}}{S^2_{C}}\sim F_{n_S-1, n_C-1}
\end{align*}\] En donde se observa que para realizar el cálculo del
estadístico, se requiere de las varianzas muestrales \(S^2_S\) y
\(S^2_C\), las cuales son iguales a
\[\begin{align*}
S^2_S &= 3.231254\\
S^2_C &= 1.378146
\end{align*}\]
encontrando entonces que el valor del estadístico de prueba es igual a
\[\begin{align*}
F_c &= \frac{3.231254}{1.378146}\\
&= 2.344638
\end{align*}\]
Ahora, para poder decidir si la hipótesis de interés se encuentra o no
apoyada por la información muestral, se realiza el cálculo de la región
crítica, la cual está dada por
\[\begin{align*}
RC:\left\{F\Bigg|F< \frac{1}{F_{\alpha, n_C -1, n_S - 1}}\right\}
\end{align*}\]
En donde se tiene que al reemplazar el valor \(\alpha = 0.10\),
\(n_C=8\) y \(n_S=10\) en el valor crítico de interés, se tendrá que
\[\begin{align*}
F_{\alpha, n_C -1, n_S - 1} &= F_{0.10, 8 - 1, 10 - 1}\\
F_{\alpha, n_C -1, n_S - 1} &= F_{0.10, 7, 9}\\
F_{\alpha, n_C -1, n_S - 1} &= 2.5053132
\end{align*}\]
En donde si se reemplaza dicho valor en el área de la región crítica, se
tendrá que \[\begin{align*}
RC&:\left\{F\Bigg|F< \frac{1}{F_{\alpha, n_C -1, n_S - 1}}\right\}\\
RC&:\left\{F\Bigg|F< \frac{1}{F_{0.10, 7, 9}}\right\}\\
RC&:\left\{F\Bigg|F< \frac{1}{2.5053132}\right\}\\
RC&:\left\{F\Bigg|F< 0.3992\right\}
\end{align*}\]
mientras que el P-valor asociado al estadístico de prueba está dado por
\[\begin{align*}
\text{P-valor}&= \mathbb{P}(F_{n_S-1, n_C-1} < F_c)\\
\text{P-valor}&= \mathbb{P}(F_{10-1, 8-1} < 2.344638)\\
\text{P-valor}&= \mathbb{P}(F_{9, 7} < 2.344638)\\
\text{P-valor}&= 0.8629449
\end{align*}\]
Encontrando con ello que al caer el estadístico de prueba por fuera de
la región crítica, y al ser el P-valor mayor al nivel de significancia
\(\alpha = 0.10\), no se encuentra evidencia muestral suficiente para
rechazar la hipótesis nula, lo cual quiere decir que con un nivel de
significancia del \(10%\) se concluye que la variabilidad de los cables
sin encapsulado no es menor a la variabilidad de los cables con
encapsulado.
en donde se aprecia que el estadístico de prueba para esta ocasión
estará dado por \[\begin{align*}
F_c=\frac{S^2_{S}}{S^2_{C}}\sim F_{n_S-1, n_C-1}
\end{align*}\] En donde se observa que para realizar el cálculo del
estadístico, se requiere de las varianzas muestrales \(S^2_S\) y
\(S^2_C\), las cuales son iguales a
\[\begin{align*}
S^2_S &= 3.231254\\
S^2_C &= 1.378146
\end{align*}\]
encontrando entonces que el valor del estadístico de prueba es igual a
\[\begin{align*}
F_c &= \frac{3.231254}{1.378146}\\
&= 2.344638
\end{align*}\]
Ahora, para poder decidir si la hipótesis de interés se encuentra o no
apoyada por la información muestral, se realiza el cálculo de la región
crítica, la cual está dada por
\[\begin{align*}
RC:\left\{F\Bigg|F< \frac{1}{F_{\alpha, n_C -1, n_S - 1}}\right\}
\end{align*}\]
En donde se tiene que al reemplazar el valor \(\alpha = 0.10\),
\(n_C=8\) y \(n_S=10\) en el valor crítico de interés, se tendrá que
\[\begin{align*}
F_{\alpha, n_C -1, n_S - 1} &= F_{0.10, 8 - 1, 10 - 1}\\
F_{\alpha, n_C -1, n_S - 1} &= F_{0.10, 7, 9}\\
F_{\alpha, n_C -1, n_S - 1} &= 2.5053132
\end{align*}\]
En donde si se reemplaza dicho valor en el área de la región crítica, se
tendrá que \[\begin{align*}
RC&:\left\{F\Bigg|F< \frac{1}{F_{\alpha, n_C -1, n_S - 1}}\right\}\\
RC&:\left\{F\Bigg|F< \frac{1}{F_{0.10, 7, 9}}\right\}\\
RC&:\left\{F\Bigg|F< \frac{1}{2.5053132}\right\}\\
RC&:\left\{F\Bigg|F< 0.3992\right\}
\end{align*}\]
mientras que el P-valor asociado al estadístico de prueba está dado por
\[\begin{align*}
\text{P-valor}&= \mathbb{P}(F_{n_S-1, n_C-1} < F_c)\\
\text{P-valor}&= \mathbb{P}(F_{10-1, 8-1} < 2.344638)\\
\text{P-valor}&= \mathbb{P}(F_{9, 7} < 2.344638)\\
\text{P-valor}&= 0.8629449
\end{align*}\]
Encontrando con ello que al caer el estadístico de prueba por fuera de
la región crítica, y al ser el P-valor mayor al nivel de significancia
\(\alpha = 0.10\), no se encuentra evidencia muestral suficiente para
rechazar la hipótesis nula, lo cual quiere decir que con un nivel de
significancia del \(10%\) se concluye que la variabilidad de los cables
sin encapsulado no es menor a la variabilidad de los cables con
encapsulado.
Prueba de bondad de ajuste
Las pruebas de bondad de ajuste son un contraste de hipótesis para determinar el grado o nivel de ajuste de nuestros datos a una distribución teórica.
Estas pruebas se basan en la comparación de las frecuencias de ocurrencia observadas en una muestra empírica y las frecuencias esperadas de una distribución teórica. En donde, el objetivo será si existe o no discrepancia entre los valores observados y los valores esperados de la distribución de interés.
La hipótesis a probar de interés estará dada por
\begin{align*} H_0: X \sim F_0(x) \quad \text{vs} \quad H_1: X \nsim F_0(x) \end{align*}
Siendo $F_0(x)$ la distribución de probabilidad hipótetica que se
quiere probar.
Entre las pruebas de bondad de ajuste más usadas se tiene:
| Prueba | Librería | Función |
|---|---|---|
| Kolmogorov–Smirnov | stats | ks.test() |
| Cramer–von Mises | goftest | cvm.test() |
| Anderson–Darling | goftest | ad.test() |
| QQPlot | car | qqPlot() |
Donde éstas pruebas, requieren de los parámetros de la distribución que se quiere probar, y para encontrarlos, es posible emplear métodos de optimización que nos permitan observar cuales son los parámetros ajustados para un conjunto de datos determinado. Para emplear estos método de optimización es posible usar la función fitdistr() de la librería MASS.
Ejercicio
Suponga que el grupo de Economía de la Salud ha realizado un estudio
sobre los contagios que se han presentado durante las últimas semanas
por el COVID-19, ya que tienen la hipótesis de la tasa de contagios
posee una distribución Weibull.
Para probar si dicha hipótesis
se encuentra apoyada o no por la información empírica, el grupo de
Economía de la Salud, ha decidido tomar como una muestra de los últimos
2 meses (61 días) sobre el número de contagios que se han presentado la
región antioqueña, encontrado los siguientes registros (en miles)
| 714 | 754 | 679 | 735 | 684 | 759 | 759 | 741 | 713 | 722 |
| 739 | 710 | 737 | 708 | 711 | 744 | 733 | 739 | 681 | 741 |
| 723 | 689 | 699 | 680 | 690 | 678 | 694 | 710 | 690 | 694 |
| 722 | 725 | 747 | 693 | 701 | 724 | 713 | 720 | 696 | 682 |
| 713 | 657 | 714 | 717 | 695 | 724 | 735 | 700 | 713 | 739 |
| 737 | 721 | 744 | 668 | 728 | 727 | 695 | 725 | 705 | 678 |
| 713 |
Si se decide emplear un nivel de significancia del \(5\%\), pruebe si las hipótesis planteadas por el grupo de la economía de la salud se encuentran o no apoyadas por la información empírica.
Solución
En este caso estamos interesados en emplear un nivel de significancia \(\alpha=0.05\) para probar si la información obtenida en \(61\) días apoya o no la hipótesis sobre que los contagios que se han presentado durante las últimas semanas por el COVID-19 poseen una distribución Weibull, esto es \[\begin{align*} H_0:X \sim Wei(\alpha,\beta)\\ H_1:X \not\sim Wei(\alpha,\beta) \end{align*}\] y para ello debemos inicialmente ajustar los parámetros de una distribución Weibull que mejor ajustan los datos, mediante la función fitdistr de la librería MASS, tal que
## Se cargan los datos
datos <- c(714, 754, 679, 735, 684, 759, 759, 741, 713, 722,
739, 710, 737, 708, 711, 744, 733, 739, 681, 741,
723, 689, 699, 680, 690, 678, 694, 710, 690, 694,
722, 725, 747, 693, 701, 724, 713, 720, 696, 682,
713, 657, 714, 717, 695, 724, 735, 700, 713, 739,
737, 721, 744, 668, 728, 727, 695, 725, 705, 678,
713)
## Se realiza el ajuste de los parámetros a una distribución Weibull
library(MASS)
parametros <- fitdistr(x = datos, densfun = "weibull")
parametros
shape scale
33.781908 724.649562
( 3.286809) ( 2.906706)
Una vez conocidos el valor de los parámetros de la distribución Weibull que ofrecen un mejor ajuste a los datos muestrales, tal que \(\alpha = 33.781908\) y \(\beta = 724.649562\), se procede al ajuste de la distribución mediante el empleo de la prueba Cramer-Von Mises, mediante la función cvm.test de la librería goftest
## Se hace el ajuste de los datos a la distribución Weibull
library(goftest)
cvm.test(x = datos, null = "pweibull", shape = parametros$estimate[1],
scale = parametros$estimate[2])
Cramer-von Mises test of goodness-of-fit
Null hypothesis: Weibull distribution
with parameters shape = 33.781908, scale =
724.649562
Parameters assumed to be fixed
data: datos
omega2 = 0.067026, p-value = 0.7718
Donde se observa que la prueba de bondad de ajuste arrojó un
P-valor\(=0.7718\), por lo cual al ser mayor que al nivel de
significancia \(\alpha=0.05\), se concluirá que no hay evidencia en
contra de rechazar la hipótesis nula de que los datos poseen una
distribución Weibull con parámetro de forma \(\alpha = 33.781908\) y
parámetro de escala \(\beta = 724.649562\).
Adicionalmente,
podemos ver el ajuste que tiene la distribución Weibull de parámetros
\(\alpha = 33.781908\) y \(\beta = 724.649562\), mediante un QQ-plot,
tal que
## Se muestra el ajuste de la distribución Weibull de forma gráfica
library(car)
qqPlot(datos, dist = "weibull", shape = parametros$estimate[1], scale = parametros$estimate[2],
envelope = 0.95)
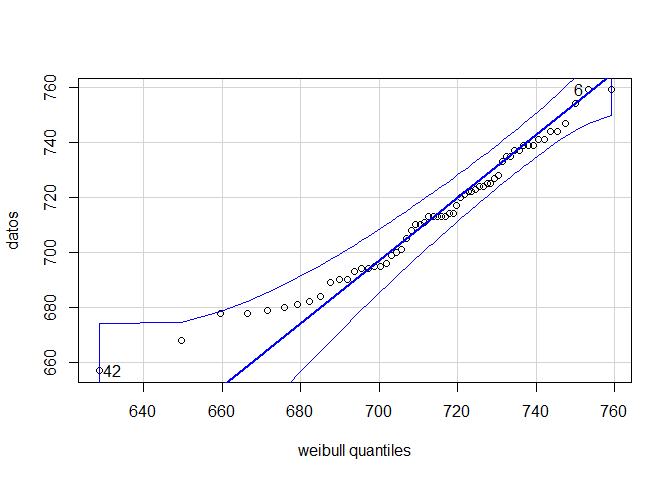
en donde se observa que todos los puntos asociados a la distirbución empírica caen dentro de los límites de confianza del \(95\%\) del QQ-plot, y por tanto se tendrá con un nivel de significancia \(\alpha=0.05\), que el número de contagios que se han presentado durante las últimas semanas por el COVID-19, posee una distribución Weibull con parámetro de forma \(\alpha = 33.781908\) y parámetro de escala \(\beta = 724.649562\).
Pruebas de normalidad
Un caso particular de las pruebas de bondad de ajuste son las pruebas específicas que permiten probar si un conjunto de datos se distribuyen o no normalmente, en donde el juego de hipótesis de interés estará dado por
\begin{align*} H_0: X \sim N(\mu,\sigma^2) \quad \text{vs} \quad H_1: X \nsim N(\mu,\sigma^2) \end{align*}
A saber, las funciones más usadas de bondad de ajuste para probar normalidad son:
| Prueba | Librería | Función |
|---|---|---|
| Shapiro-Wilk | stats | shapiro.test() |
| Lilliefors | nortest | lillie.test() |
| Shapiro-Francia | nortest | sf.test() |
| Cramer Von-Mises | nortest | cvm.test() |
| Anderson-Darling | nortest | ad.test() |
| QQPlot | car | qqPlot() |
en donde, a diferencia de las pruebas de bondad de ajuste anteriormente presentadas, éstas pruebas no requieren ajustar con anterioridad los parámetros de la distribución normal, ya que dicho procedimiento se realiza de forma interna dentro de las funciones de ajuste.
Ejercicio
Suponga que el grupo de Economía de la Salud ha realizado un estudio
sobre los contagios que se han presentado durante las últimas semanas
por el COVID-19, ya que tienen la hipótesis de la tasa de contagios
posee una distribución Normal.
Para probar si dicha hipótesis
se encuentra apoyada o no por la información empírica, el grupo de
Economía de la Salud, ha decidido tomar como una muestra de los últimos
2 meses (61 días) sobre el número de contagios que se han presentado la
región antioqueña, encontrado los siguientes registros (en miles)
| 714 | 754 | 679 | 735 | 684 | 759 | 759 | 741 | 713 | 722 |
| 739 | 710 | 737 | 708 | 711 | 744 | 733 | 739 | 681 | 741 |
| 723 | 689 | 699 | 680 | 690 | 678 | 694 | 710 | 690 | 694 |
| 722 | 725 | 747 | 693 | 701 | 724 | 713 | 720 | 696 | 682 |
| 713 | 657 | 714 | 717 | 695 | 724 | 735 | 700 | 713 | 739 |
| 737 | 721 | 744 | 668 | 728 | 727 | 695 | 725 | 705 | 678 |
| 713 |
Si se decide emplear un nivel de significancia del \(5\%\), pruebe si las hipótesis planteadas por el grupo de la economía de la salud se encuentran o no apoyadas por la información empírica.
## Se cargan los datos
datos <- c(714, 754, 679, 735, 684, 759, 759, 741, 713, 722, 739, 710, 737, 708,
711, 744, 733, 739, 681, 741, 723, 689, 699, 680, 690, 678, 694, 710, 690, 694,
722, 725, 747, 693, 701, 724, 713, 720, 696, 682, 713, 657, 714, 717, 695, 724,
735, 700, 713, 739, 737, 721, 744, 668, 728, 727, 695, 725, 705, 678, 713)
## Se hace el ajuste de los datos a la distribución Normal
library(nortest)
lillie.test(datos)
Lilliefors (Kolmogorov-Smirnov) normality test
data: datos
D = 0.066013, p-value = 0.7321
Observando que al obtener un P-valor\(=0.7321\) se tendrá que no hay
evidencia en contra de la hipótesis nula, ya que el P-valor obtenido en
la prueba de normalidad es superior al nivel de significancia
\(\alpha=0.05\), concluyendo entonces que el número de contagios que se
han presentado durante las últimas semanas por el COVID-19, posee una
distribución Normal.
Además, si realizamos el QQ-plot para
observar el ajuste de las observaciones a la distribución normal se
tiene que
## Se muestra el ajuste de la distribución Normal de forma gráfica
library(car)
qqPlot(datos, envelope = 0.95)
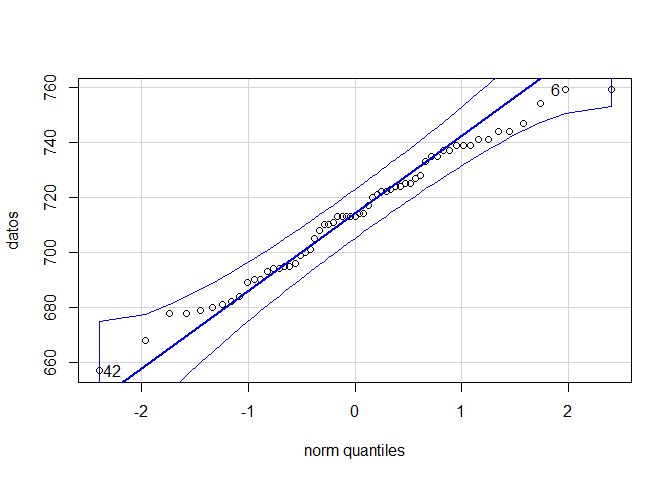
En donde se aprecia que la totalidad de los puntos asociados a los datos muestrales caen dentro de las bandas de confianza del \(95\%\) de la distribución normal, por lo cual se concluye con un nivel de significancia del \(5\%\) que el número de contagios que se han presentado durante las últimas semanas por el COVID-19, si posee una distribución Normal.