
Introducción a R
R es un lenguaje de programación interpretado orientado a objetos junto con un sistema de ventanas, que permite una interacción directa e intuitiva con el tipo de programación realizada. Este tipo de programación, posee una notable cercanía con la forma en que se expresarían las cosas en la vida real, ya que trabaja sobre objetos visibles que poseen determinadas característica, lo cual hace que puedan ser empleados para la realización de acciones específicas.
Para entender cómo se crean o manipulan objetos en R, es necesario introducir inicialmente el lenguaje de programación, y para ello lo primero que debe hacerse, es entender la estructura de asignación, los tipos de datos, las clases de los objetos y las ayudas que maneja el programa.
Estructura de asignación
La estructura de asignación del lenguaje R puede llevarse a cabo mediante cuatro formas diferentes, donde, cada una de ellas lleva al mismo resultado
variable <- objeto # Primer método
objeto -> variable # Segundo método
variable = objeto # Tercer método
assign(variable, objeto) # Cuarto método
De estos cuatro métodos de asignación presentados, el primero y el segundo poseen la misma estructura, la diferencia entre ellos radica en que, el primero realiza la asignación a la izquierda y el segundo a la derecha, lo cual depende de la dirección hacia donde apunte la flecha.
El tercer método, a pesar de realizar la asignación al igual que los dos primeros métodos, éste no es el operador habitual de asignación, pues éste se encuentra reservado para otros propósitos, tales como darle valores a una variable dentro de una función. El cuarto método, es una forma de asignación equivalente a las dos primeras, pero requiere de “más esfuerzo” para llevarse acabo la asignación.
Por lo tanto, se recomienda emplear el primer método de asignación.
Es de anotar que el símbolo <- puede escribirse de dos formas,
presionando la tecla < seguida de la tecla -, o alternativamente,
presionando de forma simultanea las teclas Alt y la tecla -.
También se señala que el carácter #, se emplea para comentar el
código o una línea específica, lo cual implica que posterior a #, no
se ejecutará ningún tipo de código en la linea específica en la cual se
encuentre #.
Tipo de datos
Existen diferentes tipos de datos en los lenguajes de programación, de estos tipos dependerá las operaciones o funciones que pueden o no emplearse con éstos, y es por ello que debe tenerse especial cuidado cuando se deseen manipular.
Los tipos de datos más que pueden encontrarse en R son:
- numeric: Datos numéricos, los cuales soportan números
que se encuentren en el conjunto de los reales,
$\mathbb{R}$, y por tanto soporta tanto números enteros (integer) y números de doble precisión (double). - integer: Datos enteros, los cuales soportan números que
se encuentren en el conjunto de los enteros,
$\mathbb{Z}$, y en consecuencia, solo soporta números enteros. - complex: Datos complejos, los cuales soportan números
que se encuentren en el conjunto de los complejos,
$\mathbb{C}$, y por tanto, soporta tanto números reales como imaginarios. - character: Datos de carácter, los cuales soportan caracteres alfanuméricos, es decir, datos numéricos y alfabéticos. Éstos deben ser escritos entre comillas simples o dobles.
- factor: Datos categóricos nominales, los cuales soportan caracteres alfanuméricos, y establece entre estos diferentes categorías. Se puede emplear la función factor() para crear datos de este tipo. Éstos deben ser escritos entre comillas simples o dobles.
- ordered: Datos categóricos ordinales, los cuales soportan caracteres alfanuméricos, y establece entre estos diferentes categorías junto con una estructura jerárquica. Se puede emplear la función ordered() para crear datos de este tipo. Éstos deben ser escritos entre comillas simples o dobles.
- logical: Datos lógicos, los cuales soportan caracteres lógicos tales como TRUE o FALSE.
Para verificar al estructura de almacenamiento en R, puede emplearse la función str(), mientras para observar la estructura de almacenamiento pueden emplearse las funciones mode(), typeof, y para observar la clase interna del objeto puede emplearse la función class().
A continuación se presenta un ejemplo en donde se muestran los diferentes tipos de objetos en R
Dato tipo numérico
# Numeric
a <- 3.3
str(a)
num 3.3
Dato tipo entero
# Integer
b <- 3L
str(b)
int 3
Dato tipo lógico
# Complex
c <- 3 + (0+0.2i)
str(c)
cplx 3+0.2i
Dato tipo carácter
# Character
d <- "Ejemplo :D"
str(d)
chr "Ejemplo :D"
Dato tipo factor
# Factor
e <- factor("Otro ejemplo :o")
str(e)
Factor w/ 1 level "Otro ejemplo :o": 1
Dato tipo ordinal
# Ordered
f <- ordered("Uno más >:o")
str(f)
Ord.factor w/ 1 level "Uno más >:o": 1
Dato tipo lógico
# logic
g <- FALSE
str(g)
logi FALSE
Clases de objetos
Adicionalmente, con el fin de organizar los datos, se presentan algunas de las clases de objetos más comúnmente usados en R
- Vector: este objeto admite datos numéricos, caracteres,
complejos o lógicos, pero solo permite un solo tipo de dato a la
vez. Puede construirse mediante la función
c().
Representación de un Vector
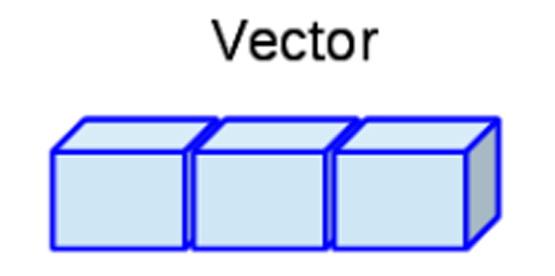
Ejemplo en R
vecN <- c(1, 4, 5, -6.2, 2, -3) # Númerico
vecC <- c("a", "c", "a", "b", "c", "a") # Alfanumérico
vecL <- c(F, T, NA, F, T, F) # Lógico
- Matriz: este objeto admite datos numéricos, caracteres,
complejos o lógicos, pero solo permite un solo tipo de dato a la
vez. Puede construirse mediante la función
matrix().
Representación de un Matriz
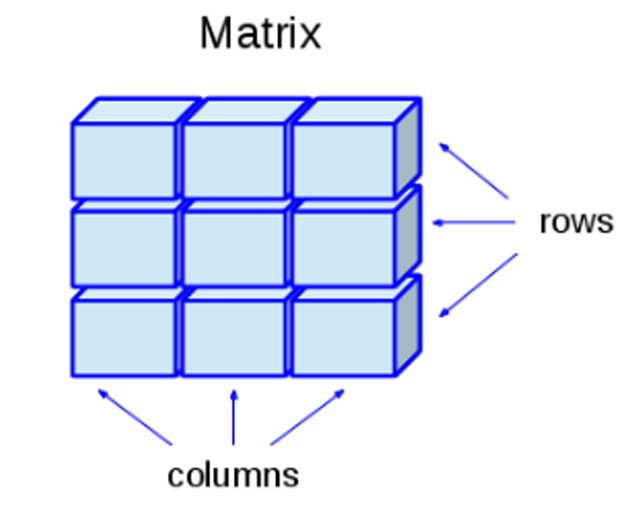
Ejemplo en R
matN <- matrix(data = c(1, 4, 5, 6, 2, 3), nrow = 3, ncol = 2, byrow = T) # Númerico
matC <- matrix(data = c("a", "c", "a", "b", "c", "a"), nrow = 2, ncol = 3, byrow = F) # Alfanumérico
matL <- matrix(data = c(vecL, T, T, F), nrow = 3, ncol = 3, byrow = F) # Lógico
rownames(matN) <- c("F1", "F2", "bla") # Poner nombre filas
colnames(matN) <- c("D:", "C2") # Poner nombre columnas
matV <- matrix(data = c(-5, -6, 8.1, 12.3, 2, -1), nrow = 1) # Crear vector con función matrix
- Marco de Datos: Permite datos numéricos, caracteres, complejos o
lógicos, además de permitir múltiples tipos por objeto a la vez.
Puede construirse mediante la función
data.frame().
Representación de un Marco de Datos
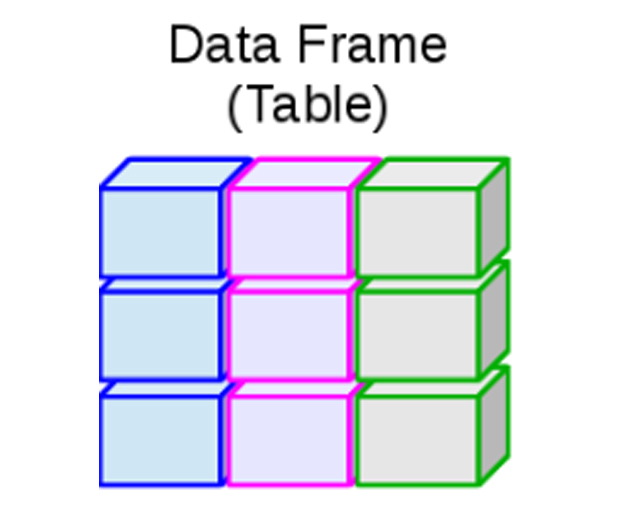
Ejemplo en R
dataf <- data.frame(cbind(vecN, vecC, vecL))
# Las funciones cbind() y rbind() combinan vectores, matrices o data-frame
# por columna o fila, respectivamente.
- Arreglos: Permite datos numéricos, caracteres, complejos o
lógicos, pero solo permite un solo tipo de dato a la vez. Puede
construirse mediante la función
array().
Representación de un Arreglo
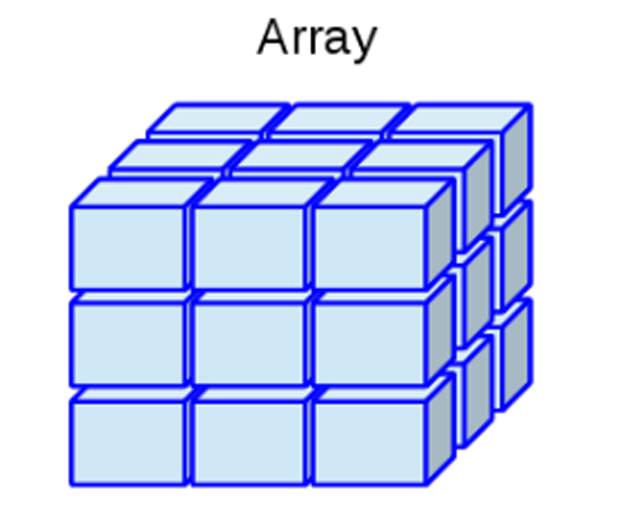
Ejemplo en R
arrN <- array(data = c(1, 4, 5, 6, 2, 3, 2, 3, 4, 1, 2, 4), dim = c(3, 2, 2)) # Númerico
arrC <- array(data = c(vecC, "o", "m"), dim = c(2, 2, 2)) # Alfanumérico
arrL <- array(data = c(vecL, F, F, NA, F, T, NA), dim = c(2, 2, 3)) # Lógico
arrV <- array(data = c(-5, -6, 8.1, 12.3, 2, -1)) # Crear vector con función array
arrM <- array(data = vecC, dim = c(2, 3, 1)) # Crear matriz con función array
- Listas: Permite datos numéricos, caracteres, complejos, lógicos,
funciones, expresiones, etc, además de permitir múltiples tipos por
objetos a la vez. Puede construirse mediante la función
list().
Representación de listas
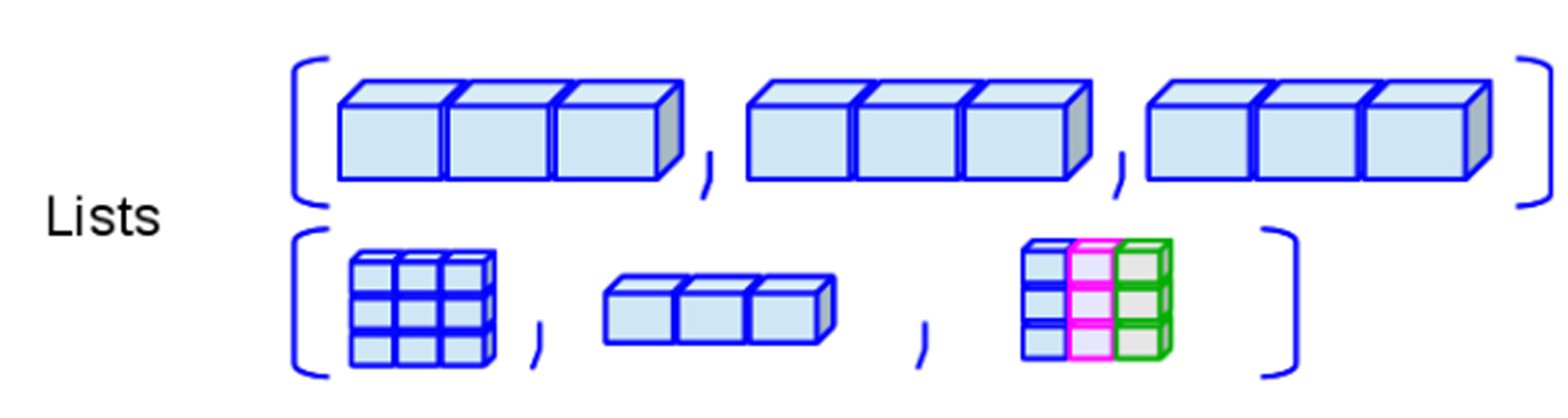
Ejemplo en R
listica <- list(dataf, matN, expression(beta))
Ayuda sobre funciones
Para obtener información sobre una función concreta o carácter en
R, existen dos métodos que permiten abrir la ventana de ayuda,
el primero es mediante la función help(), la segunda es
mediante el signo ?. Para ilustrar dichos métodos, empleamos la
función if() y el carácter +, para consultar su
ventana de ayuda.
help("if") # Primer método
?"+" # Segundo método
La estadística en políticas públicas
Las políticas públicas tienen como finalidad abordar problemas sociales que requieren de intervención desde el ámbito público, que tienen como finalidad gestionar planes, programas o proyectos que permitan dar solución de la mejor manera a dichos problemas.
Cada una de las estrategias que buscan dar solución a los problemas sociales, requieren de procesos de seguimiento y evaluación, cuyo papel puede ser igual o más importante que el objetivo mismo que se desea alcanzar. Ésto debido a que, los procesos de seguimiento y evaluación permiten analizar la planificación realizada para retroalimentar el proceso de ejecución a través de la medición del impacto que generan las políticas para la comunidad. (Recchioni, 2016, p. 162)
Es aquí donde la estadística toma relevancia dentro de las políticas públicas, puesto que el análisis estadístico es una herramienta indispensable en el análisis cualitativo o cuantitativo de información, lo cual hace que se convierta en una parte esencial en el momento de diseñar planes de evaluación de políticas.
Es debido a lo anterior que, todo expertos en políticas públicas, debe desarrollar una fuerte fundamentación en análisis de datos, ya que deben enfrentarse continuamente a problemas que requieren la tomar decisiones, basados en informes estadísticos descriptivos o inferenciales, que tiene por finalidad apoyar la formulación, implementación, gestión o evaluación de políticas públicas.
Introducción a la estadística
La Estadística es una herramienta ampliamente utilizada en diferentes disciplinas científicas, debido a su gran potencial para recolectar, analizar, interpretar, estimar y presentar de forma amigable, la información que se genera en las distintas áreas del conocimiento, para así poder argumentar y soportar de mejor manera las investigaciones realizadas, y/o mejorar los resultados obtenidos en la toma de decisiones.
Adicionalmente, la estadística tiene como ventaja respecto a otras áreas, que permite extraer información de variables tanto númerida como categórica de la población de interés o de una muestra de la misma, permitiendo al investigador establecer conclusiones acerca de la misma población, o de alguno de los parámetros que la conforman. Y es debido a ésto, que puede considerarse a la estadística como uno de los pilares fundamental dentro de la investigación científica teórica y aplicada.
En general, el análisis estadístico puede dividirse en dos partes:
- La Estadística descriptiva, la cual se encarga de resumir la información suministrada mediante el empleo de tablas, gráficas y medidas numéricas, junto con el análisis de las mismas, para facilitar la interpretación y la presentación de la información.
- La Inferencia estadística, la cual se encarga de la inferencias, modelamiento y predicción de la información, para facilitar la obtención de conclusiones y toma decisiones.
Estadística descriptiva
En general, la importancia del análisis estadístico radica en la resolución de problemas vinculados con datos, en donde la variabilidad de los mismos es quién guiará la importancia del empleo de diferentes técnicas para el manejo de la información. Desde este punto de vista, se discute en esta sección sobre la implementación de resúmenes de información, así como la presentación por medio de cuadros, diagramas o gráficos, cálculo y uso de medidas estadísticas de tendencia central, localización, variabilidad y forma.
Un aspecto importante a tener en cuenta en realización de análisis estadísticos, es señalado por Esquivel (2016, p. 29), el cual establece una serie de etapas que deben tenerse en cuenta cuando se realizan análisis de información estadística:
- Leer entre los datos: que consiste en llevar a cabo una lectura literal de la información, sin interpretar su contenido.
- Leer dentro de los datos: implica no solamente interpretar los datos sino integrarlos dentro del contexto.
- Leer más allá de los datos: significa tomar los datos como referente para identificar patrones que transciendan el grupo de datos observado, ya sea mediante la interpolación o extrapolación de resultados.
- Leer detrás de los datos: consiste en llevar a cabo un análisis crítico de la información que se estudia, esto implica analizar integralmente el problema, desde su origen, el tipo de dato que se utiliza, su validez y fiabilidad para analizar el problema y la posibilidad de generalizar los hallazgos.
Pre-prosesamiento de datos
La limpieza o pre-procesamiento de los datos es uno de los aspectos
más importantes cuando se desea trabajar con conjuntos de datos, a tal
punto que muchos investigadores aseguran que en este procedimiento se
emplea regularmente desde el $50\%$ hasta el $80\%$ del tiempo total
de una investigación.
El objetivo principal de la limpieza de datos, es el asegurar la calidad de la información que se usará en los análisis, además de minimizar el riesgo en la toma de decisiones, en base a información perdida, poco precisa, duplicada, contradictoria, errónea o incompleta, ya qué ésta podría influir significativamente en los resultados estadísticos y conclusiones.
Uno de los primeros procedimientos en la limpieza de datos, corresponde en transformar los datos sin procesar a datos técnicamente correctos, y para ello es necesario corregir aquellos problemas que pueden generarse en el momento de realizar la lectura de datos, que pueden impedir o complicar la manipulación de la base de datos.
Dichos problemas están relacionados con, el hallazgo de caracteres especiales, tipos o clases incorrectos para los conjuntos de datos, datos faltantes, datos duplicados, entre otros.
En la segunda fase, corresponde en transformar los datos técnicamente correcto a datos consistentes, para lograr llevar los datos a una etapa en la que el conjunto de observaciones están listos para la realización estadística descriptiva e inferencial.
Este procedimiento consta en solucionar problemas relacionados con datos faltantes o datos duplicados, que inflan la totalidad de la información que se posea.
Caso de estudio y variables
Como caso de estudio para esta sesión, se propone una base de datos
construida a partir del $10\%$ de la información contenida en el Censo
de Edificaciones que posee el DANE para el periodo comprendido entre
2012-2018. Dicha base de datos puede ser descargada desde el siguiente
Link.
Variables base de datos
Las variables contenidas en la base de datos anterior son:
- ANO\(\color{#28c74c}{\_}\)CENSO: Año al que corresponde la información recolectada en el Censo.
- TRIMESTRE: Trimestre al que corresponde la información recolectada en el Censo.
- REGION: Región de acuerdo con las áreas urbanas y metropolitanas en las cuales se realiza la publicación de la información.
- 5 = Antioquia
- 66 = Risaralda
- 11 = Bogotá
- 63 = Quindío
- 76 = Valle
- 54 = Norte de Santander
- 50 = Meta
- 8 = Atlántico
- 41 = Huila
- 68 = Santander
- 13 = Bolívar
- 52 = Nariño
- 19 = Cauca
- 73 = Tolima
- 17 = Caldas
- OB\(\color{#28c74c}{\_}\)FORMAL: Define si la obra cuenta o no con licencia de construcción
- 1 = Si
- 2 = No
- ESTADO\(\color{#28c74c}{\_}\)ACT: El estado determina como se encontró la obra al momento del censo y se capta el código correspondiente.
- 1 = Proceso
- 2 = Paralizada con información completa
- 3 = Culminada completa
- 4 = Paralizada incompleta
- 5 = Culminada con información incompleta
- 6 = Demolida
- MOVIMIENTO: El movimiento es el código de cambio de estado
- C = Continua
- I = Inactiva
- N = Nueva
- A = Ampliación cobertura
- R = Reinicia
- T = Culmina
- D = Demolida
- ESTRATO: Clasificación dada por las empresas de servicios públicos. División numérica que caracteriza el entorno socio económico de un espacio geográfico y arquitectónico determinado
- 1 = Bajo bajo
- 2 = Bajo
- 3 = Medio bajo
- 4 = Medio
- 5 = Medio Alto
- 6 = Alto
- AREATOTZC: Área total de zonas comunes cubiertas (incluido garaje y los depósitos o cuartos útiles como: portería, salones comunales, pasillos, etc.).
- AREAUNITGA: Metros cuadrados de la unidad de garaje (cubiertos).
- PRECIOUNIG: Valor de las unidades de garaje cubierto en miles de pesos.
- TIPOVALOR: Tipo de valor de garaje cubierto
- 1 = Real
- 2 = Estimado
- MANO\(\color{#28c74c}{\_}\)OBRAP: Corresponde a la cantidad de mano de obra permanente generada en el período intercensal por tipo de mano de obra.
- MANO\(\color{#28c74c}{\_}\)OBRAT: Corresponde a la cantidad de mano de obra temporal generada en el período intercensal por tipo de mano de obra.
- AREA\(\color{#28c74c}{\_}\)LOTE: Corresponde al área del terreno donde se construye la obre o proyecto.
- AREAVENDIB: Área total vendible (no incluye garaje y los depósitos o cuartos útiles).
- NRO\(\color{#28c74c}{\_}\)PISOS: Número de pisos del destino corresponde al número de pisos que conformarán cada destino que este en proceso de construcción.
- GRADOAVANC: Grado de avance. Porcentaje de avance de obra del capítulo constructivo.
- PRECIOVTAX: Precio de venta por M2 del destino, sin incluir garaje, en miles de pesos.
- AREAVENUNI: Área total vendible por unidad (no incluye garaje y los depósitos o cuartos útiles).
- TIPOVIVI: Tipo de vivienda hace referencia a si el destino es vivienda de interés social o no. Valor calculado
- 1 = Vivienda de interés social
- 2 = Vivienda diferente de VIS
- RANVIVI: Rango de vivienda, valor calculado
- 1 = SMLMV < 50
- 2 = 50 < SMLMV ≤ 70
- 3 = 70 < SMLMV ≤ 100
- 4 = 100 < SMLMV ≤ 135
- 5 = 135 < SMLMV ≤ 350
- 6 = SMLMV ≥ 350
- Destino2: Identificación de la obra, según tipo o uso de la edificación, que se está construyendo.
- 1 = Apartamento
- 2 = Oficinas
- 3 = Comercio
- 4 = Casas
- 5 = Bodegas
- 6 = Destinos no comercializables (educación, hoteles, hospitales y centros de salud, administración pública y otros)
Lectura de datos en R
Para realizar la lectura de datos en R es necesario conocer la extensión que posee el archivo de interés, debido a que R posee diferentes librerías y funciones que permiten la lectura de bases de datos. En la siguiente tabla se resume el origen, la extensión, la librería, y la función para cargar cada base de datos dependiendo de su extensión.
| Origen | Extensión | Librería | Función |
|---|---|---|---|
| Texto | .txt | utils* | read.table() |
| Texto | .csv (comas) | utils* | read.csv() |
| Texto | .csv (punto y coma) | utils* | read.csv2() |
| Excel | .xls | readxl | read_xls() |
| Excel | .xlsx | readxl | read_xlsx() |
| SPSS | .sav | foreign | read.spss() |
| SAS | .sas7bdat | foreign | read.ssd() |
| STATA | .dta | foreign | read.dta() |
Nota: Las librerías con * hacen referencia a funciones integradas en R, y en consecuencia, no es necesario cargarlas antes de usarlas.
Ejemplo lectura de datos
A modo de ejemplo, suponga que se desea cargar una base de datos de excel con extensión .xlsx **mediante la búsqueda del archivo en el ordenador**. En este caso será necesario cargar la librería readxl y posteriormente, cargar la base de datos mediante la función read.xlsx() que sirve para cargar archivos con extensión xlsx, y la función file.choose() que permite buscar el archivo en el ordenador.
## Código de ejemplo NO CORRER
library(readxl)
datos <- read_xlsx(file.choose())
Por otro lado, suponga que deseamos cargar una base de datos de STATA con extensión .dta **de forma automática**. En este caso será necesario cargar la librería foreign y posteriormente, cargar la base de datos mediante la función read.dta(), estableciendo la localización en donde se encuentra el archivo en el ordenador.
## Código de ejemplo NO CORRER
library(foreign)
datos <- read.dta("C:/Users/user/Desktop/datos.dta")
Finalmente, suponga que se desea cargar una base de datos de Texto con extensión .csv, la cual usa como separador de columnas el punto y coma (;). En este caso será necesario descargar el archivo en una locación temporal, mediante las funciones tempfile() y download.file, y posteriormente, emplear la función read.cvs2(), de la forma
## Código de ejemplo CORRER :D
temp <- tempfile(fileext = ".cvs") # Crea archivo temporal
URL <- "https://raw.githubusercontent.com/jiperezga/jiperezga.github.io/master/Dataset/CesoEdificaciones2012-2018.csv" # URL base de datos
download.file(URL, destfile = temp, mode = "wb") # Descarga archivo en el archivo temporal creado
datos <- read.csv2(temp)
Limpieza de datos (Datos sin procesar a datos ténicamente correctos)
Corrección encabezados en R
En muchas ocasiones, podemos enfrentarnos a bases de datos que poseen problemas en el nombre de los encabezados, asociados caracteres especiales tales como ! “ # $ % & ’ ( ) * + , - . / : ; < = > ? @ [ ] ^ _ ` { | } ~, o abuso de letras mayúsculas en los encabezados, entre otros.
Por ello es necesario luego de cargar la base de datos, verificar si tales problemas existen para poder corregirlos de alguna manera. A pesar de que en nuestro caso, no hay problemas de caracteres especiales poseemos el problema del abuso de letras mayúsculas en el nombre de las variables, lo cual podría ser tedioso en la programación, debido a que R diferencia entre caracteres en mayúscula y minúscula.
Con el fin de darle solución a dicho problema, es posible emplear la función clean_names() de la librería janitor, con el fin de
- Analizar las mayúsculas y minúsculas y separadores a un formato consistente.
- Maneja caracteres y espacios especiales.
- Agrega números a nombres duplicados.
- Convierte “%” en “percent” y “#” en “number” para conservar el significado de la variable.
Ejemplo limpieza encabezados
Se observa inicialmente la estructura inicial de los nombres que posee la base de datos
# Se observa el nombre de las variables
names(datos)
[1] "ANO_CENSO" "TRIMESTRE" "REGION" "OB_FORMAL" "AMPLIACION"
[6] "ESTADO_ACT" "MOVIMIENTO" "ESTRATO" "AREATOTZC" "AREAUNITGA"
[11] "PRECIOUNIG" "TIPOVALOR" "MANO_OBRAP" "MANO_OBRAT" "AREA_LOTE"
[16] "AREAVENDIB" "NRO_PISOS" "GRADOAVANC" "PRECIOVTAX" "AREAVENUNI"
[21] "TIPOVIVI" "RANVIVI" "Destino2"
De lo anterior se observa que, a pesar de no poseer caracteres especiales, los encabezados se encuentran escritos con mayúsculas sostenidas, por lo cual se procede a realizar la limpieza de los mismos con la función clean\(\_\)names() de la librería janitor.
# Elimina algunos caracteres especiales y abuso de mayúsculas
library(janitor)
datos <- clean_names(datos)
# Se observa el nombre de las variables
names(datos)
[1] "ano_censo" "trimestre" "region" "ob_formal" "ampliacion"
[6] "estado_act" "movimiento" "estrato" "areatotzc" "areaunitga"
[11] "preciounig" "tipovalor" "mano_obrap" "mano_obrat" "area_lote"
[16] "areavendib" "nro_pisos" "gradoavanc" "preciovtax" "areavenuni"
[21] "tipovivi" "ranvivi" "destino2"
Corrección contenido de base de datos en R
Similar a los encabezados, puede ocurrir que se encuentren problemas en los valores contenidos dentro de cada variable, a causa de caracteres especiales o espacios, que puede generar que al transformar las variables se creen categorías extras, o se pierdan datos numéricos.
Para dar solución a dicho problema, se pueden emplear en cojunto las funciones lapply() y gsub() de la base de R, para eliminar caracteres especiales y espacios dentro de la totalidad de la base de datos. Posteriormente, se debe emplear la función data.frame para que el conjunto de datos vuelva a tomar la estructura de una base de datos. Dicho procedimiento se presenta en el siguiente ejemplo.
Ejemplo corrección contenido de base de datos
Suponga que se desean corregir aquellos valores o caracteres especiales que pueden llegar a poner problema a la hora de manipular la base de datos, puede emplearse el siguiente código con cualquier base de datos.
# Elimina carácteres especiales y espacios dentro de la base de datos
datos <- lapply(datos, function(x) gsub("[[:punct:] [:blank:]]", "", x))
datos <- data.frame(datos, stringsAsFactors = F)
Tipos de datos y escalas de medicción
En términos generales, los datos son cualquier pieza de información recolectada del fenómeno que se pretende analizar, y que, dependiendo de las características que posean, deben clasificarse dentro de una determinada categoría junto a una determinada escala de medición.
- Cuantitativos: Son datos que pueden ser medidos o cuantificados.
Estos se subdividen en dos categorías:
- Discretos: Son aquellos datos que provienen de procesos que involucran conteos, y por tanto, solo pueden tomar valores enteros. Por ejemplo: Edad de una persona, número de estudiantes que perdieron un curso, cantidad de profesores que dictan seminarios
- Continuos: Son aquellos datos que provienen de procesos que involucran mediciones, y por tanto, solo pueden tomar cualquier valor real dentro de un intervalo. Por ejemplo: Temperatura de congelación del agua, Tiempo que dura una clase, Utilidad diaria de un negocio.
- Cualitativos: Son datos asociados a una cualidad o propiedad, y
por tanto, no pueden representarse numéricamente, a pesar de poder
caracterizarse alfanúmericamente.
- Nominal: Son aquellos factores que establecen etiquetas o categorías a los datos, sin estar sujetos a un orden específico. Por ejemplo: Partido político, Comuna de residencia, Tipo de animales en una granja
- Ordinal: Son aquellos factores que establecen etiquetas o categorías a los datos, junto a una estructura jerárquica. Por ejemplo: Estrato socioeconómico, Nivel de una enfermedad, Grado de escolaridad
Estructura de datos en R
Para observar la estructura de los datos en R puede emplearse la función str(), la cual muestra la forma cómo está siendo leída la información contenida en la base de datos por el programa.
Ejemplo estructura de datos en R
# Estructura de los datos
str(datos)
'data.frame': 94432 obs. of 23 variables:
$ ano_censo : chr "2012" "2015" "2016" "2013" ...
$ trimestre : chr "2" "2" "2" "2" ...
$ region : chr "41" "54" "76" "52" ...
$ ob_formal : chr "2" "2" "2" "1" ...
$ ampliacion: chr "2" "2" "2" "2" ...
$ estado_act: chr "1" "1" "1" "1" ...
$ movimiento: chr "N" "N" "N" "N" ...
$ estrato : chr "2" "4" "4" "3" ...
$ areatotzc : chr "0" "0" "0" "590" ...
$ areaunitga: chr "0" "0" "0" "11" ...
$ preciounig: chr "0" "0" "0" "6000" ...
$ tipovalor : chr "0" "0" "0" "2" ...
$ mano_obrap: chr "0" "0" "0" "1" ...
$ mano_obrat: chr "3" "4" "3" "34" ...
$ area_lote : chr "84" "79" "85" "14548" ...
$ areavendib: chr "63" "155" "156" "7939" ...
$ nro_pisos : chr "1" "2" "2" "16" ...
$ gradoavanc: chr "30" "30" "50" "10" ...
$ preciovtax: chr "1200" "1160" "995" "1340" ...
$ areavenuni: chr "63" "155" "156" "62" ...
$ tipovivi : chr "1" "2" "2" "2" ...
$ ranvivi : chr "4" "5" "5" "5" ...
$ destino2 : chr "4" "4" "4" "1" ...
Coerción de datos en R
Muchas veces cuando tenemos una variable, puede que esta no tenga almacenados los datos bajo el tipo que queremos tenerlo realmente, por ello, será necesario transformar (coercionar) cada variable, que permita ajustar la variable a tipo deseado. En R existen funciones que permiten redefinir una variable, para transformarlo al tipo que necesitamos. Estás funciones son
- as.numeric(): Convierte una variable a tipo numérico (double).
- as.logical(): Convierte una variable a tipo lógico.
- as.integer(): Convierte una variable a tipo entero.
- factor(): Convierte una variable a tipo factor asumiendo o no un orden o jerarquía entre los niveles.
- as.character(): Convierte una variable a tipo carácter (character).
Ejemplo coerción de variables en R
En nuestro caso, tenemos que todas las variables aparecen como si fuesen variables de tipo carácter, debido al procedimiento de la corrección que se hizo para eliminar caracteres especiales y espacios dentro de la base de datos. En consecuencia, debemos transformar cada variable dependiendo de su estructura y escala de medición.
En sí, tenemos que en primer lugar, las variables ano\(\_\)censo, trimestre, estrato y ranvivi son variables cualitativas ordinales y por ello deben se transformadas a variables de tipo factor ordinal. En segundo lugar, las variables region, ob\(\_\)formal, estado\(\_\)act, movimiento, tipovalor, tipovivi y destino2 son variables cualitativas nominales y deben ser transformadas a variables de tipo factor. Finalmente, las demás son variables cuantitativas discretas o continuas que pueden trabajarse como variables de tipo numéricas o enteros.
Para llevar a cabo la transformación, podemos emplear la función factor() para realizar el cambio de las variables cualitativas ordinales, la función factor() para realizar el cambio de las variables cualitativas nominales y la función as.numeric() para realizar el cambio de las variables a tipo numérica.
# Coerción de variable por variable
datos$ano_censo <- factor(datos$ano_censo, ordered = T)
datos$trimestre <- factor(datos$trimestre, ordered = T)
datos$region <- factor(datos$region, levels = c(5, 8, 11, 13, 17, 19, 41, 50, 52,
54, 63, 66, 68, 73, 76), labels = c("Antioquia", "Atlántico", "Bogotá", "Bolívar",
"Caldas", "Cauca", "Huila", "Meta", "Nariño", "Norte de Santander", "Quindío",
"Risaralda", "Santander", "Tolima", "Valle"))
datos$ob_formal <- factor(datos$ob_formal, level = c(1, 2), labels = c("Sí", "No"))
datos$estado_act <- factor(datos$estado_act, level = c(1, 2, 3, 4, 5, 6), labels = c("Proceso",
"ParalizadaInfC", "CulminadaInfC", "ParalizadaInfI", "CulminadaInfI", "Demolida"))
datos$movimiento <- factor(datos$movimiento, levels = c("A", "C", "I", "N", "R",
"T"), labels = c("Ampliación", "Continua", "Inactiva", "Nueva", "Reinicia", "Culmina"))
datos$estrato <- factor(datos$estrato, ordered = T)
datos$areatotzc <- as.numeric(datos$areatotzc)
datos$areaunitga <- as.numeric(datos$areaunitga)
datos$preciounig <- as.numeric(datos$preciounig)
datos$tipovalor <- factor(datos$tipovalor, level = c(0, 1, 2), labels = c("No responde",
"Real", "Estimado"))
datos$mano_obrap <- as.numeric(datos$mano_obrap)
datos$mano_obrat <- as.numeric(datos$mano_obrat)
datos$area_lote <- as.numeric(datos$area_lote)
datos$areavendib <- as.numeric(datos$areavendib)
datos$nro_pisos <- as.numeric(datos$nro_pisos)
datos$gradoavanc <- as.numeric(datos$gradoavanc)
datos$preciovtax <- as.numeric(datos$preciovtax)
datos$areavenuni <- as.numeric(datos$areavenuni)
datos$tipovivi <- factor(datos$tipovivi, level = c(1, 2), labels = c("Social", "No Social"))
datos$ranvivi <- factor(datos$ranvivi, ordered = T)
datos$destino2 <- factor(datos$destino2, level = c(1, 2, 3, 4, 5, 6), labels = c("Apartamento",
"Oficina", "Comercio", "Casas", "Bodega", "Otros"))
# Estructura de los datos
str(datos)
'data.frame': 94432 obs. of 23 variables:
$ ano_censo : Ord.factor w/ 7 levels "2012"<"2013"<..: 1 4 5 2 7 5 5 1 3 6 ...
$ trimestre : Ord.factor w/ 4 levels "1"<"2"<"3"<"4": 2 2 2 2 1 4 1 4 1 1 ...
$ region : Factor w/ 15 levels "Antioquia","Atlántico",..: 7 10 15 9 4 11 3 3 3 8 ...
$ ob_formal : Factor w/ 2 levels "Sí","No": 2 2 2 1 1 1 2 1 1 2 ...
$ ampliacion: chr "2" "2" "2" "2" ...
$ estado_act: Factor w/ 6 levels "Proceso","ParalizadaInfC",..: 1 1 1 1 1 1 1 1 1 1 ...
$ movimiento: Factor w/ 6 levels "Ampliación","Continua",..: 4 4 4 4 4 4 4 4 4 4 ...
$ estrato : Ord.factor w/ 6 levels "1"<"2"<"3"<"4"<..: 2 4 4 3 4 3 4 3 3 1 ...
$ areatotzc : num 0 0 0 590 1820 1990 0 390 0 0 ...
$ areaunitga: num 0 0 0 11 12 11 0 0 0 0 ...
$ preciounig: num 0 0 0 6000 20000 16000 0 0 0 0 ...
$ tipovalor : Factor w/ 3 levels "No responde",..: 1 1 1 3 3 3 1 1 1 1 ...
$ mano_obrap: num 0 0 0 1 1 3 0 10 2 0 ...
$ mano_obrat: num 3 4 3 34 25 20 3 70 36 2 ...
$ area_lote : num 84 79 85 14548 1661 ...
$ areavendib: num 63 155 156 7939 13581 ...
$ nro_pisos : num 1 2 2 16 14 10 2 6 3 1 ...
$ gradoavanc: num 30 30 50 10 2 15 50 60 10 80 ...
$ preciovtax: num 1200 1160 995 1340 4150 1450 1600 1200 2550 580 ...
$ areavenuni: num 63 155 156 62 206 66 150 49 85 68 ...
$ tipovivi : Factor w/ 2 levels "Social","No Social": 1 2 2 2 2 2 2 1 2 1 ...
$ ranvivi : Ord.factor w/ 6 levels "1"<"2"<"3"<"4"<..: 4 5 5 5 6 5 5 4 6 2 ...
$ destino2 : Factor w/ 6 levels "Apartamento",..: 4 4 4 1 1 1 4 1 4 4 ...
Limpieza de datos (Datos ténicamente correctos a datos consistentes)
Remover filas o columnas vacías en R
Este procedimiento, permite buscar y eliminar aquellas filas o columnas que se encuentran totalmente vacías y que pueden de alguna manera inflar la totalidad de información que se posee en la base de datos.
Para ello se emplea la función remove_empty() de la librería janitor.
Ejemplo remover filas o columnas vacías en R
Dado que se tiene la sospecha de que hay filas o columnas vacías en la base de datos, se emplea la función remove\(\_\)empty() de la librería janitor, tal que
# Muestra dimensión de filas y columnas antes de la eliminación
dim(datos)
[1] 94432 23
# Elimina filas y columnas que poseen solo valores NA
datos <- remove_empty(datos, which = c("rows", "cols"))
# Muestra dimensión de filas y columnas despues de la eliminación
dim(datos)
[1] 94281 23
Remover filas duplicadas en R
Este procedimiento se emplea preferiblemente cuando se posee una variable de identificación única, tal como cédula o nit, que permita comparar cada fila y eliminar solo aquellas que realmente se encuentren duplicadas.
Para eliminar las filas que se encuentren duplicadas, es posible emplear la función distinct() de la librería dplyr.
Ejemplo remover filas duplicadas en R
Dado que se tiene la sospecha de que hay filas duplicadas en la base de datos, se emplea la función distinct() de la librería dplyr, tal que
library(dplyr)
# Muestra dimensión de filas y columnas antes de la eliminación
dim(datos)
[1] 94281 23
# Elimina filas que poseen registros duplicados
datos <- distinct(datos)
# Muestra dimensión de filas y columnas despues de la eliminación
dim(datos)
[1] 86148 23
Detección de datos faltantes en R
La detección de datos faltantes radica en localizar para cada variable,
si se encuentran casillas vacías, valores especiales, tales como
Na, NaN o
NULL.
NA(Not Available): Es un carácter especial para indicar valores perdidos. Éstos pueden ser detectados en R mediante la función is.na().NaN(Not a number): Es un carácter especial para datos de clase numérica, para indicar un valor asociado a un cálculo cuyo resultado es desconocido, el cual seguramente no es un número. Este puede obtenerse mediante operaciones tales como$0/0$,$Inf/Inf$,$Inf-Inf$. Éstos pueden ser detectados en R mediante la función is.nan(), aunque también son detectados por la función is.na().NULL: Es un carácter especial para indicar valores indefinidos o indicar la no existencia de valor dentro de la base de datos o de una entrada de la misma. Éstos pueden ser detectados en R mediante la función is.null().
Para detectar aquellas filas que se encuentren faltantes dentro de una base de datos, podemos usar una combinación entre las funciones apply(), which(), tal como se muestra en la siguiente linea de código, adicionando las funciones is.na() e is.null(), dentro de la función which().
Ejemplo detección de datos faltantes en R
Con el fin de detectar si existen o no datos faltantes dentro de una base de datos puede emplearse el siguiente código
## Detectar NA, NaN y NULL dentro de la base de datos
faltantes <- apply(X = datos, MARGIN = 2, FUN = function(x) which(is.na(x) | is.null(x) |
x == "Na" | x == "NA" | x == "NaN")) # se pueden agregar más caracteres
faltantes
$ano_censo
integer(0)
$trimestre
integer(0)
$region
integer(0)
$ob_formal
integer(0)
$ampliacion
integer(0)
$estado_act
integer(0)
$movimiento
[1] 69018
$estrato
integer(0)
$areatotzc
[1] 15450 26675 48622 85119
$areaunitga
integer(0)
$preciounig
[1] 46372
$tipovalor
integer(0)
$mano_obrap
[1] 36956
$mano_obrat
[1] 49959
$area_lote
integer(0)
$areavendib
integer(0)
$nro_pisos
[1] 51050
$gradoavanc
integer(0)
$preciovtax
integer(0)
$areavenuni
integer(0)
$tipovivi
integer(0)
$ranvivi
integer(0)
$destino2
integer(0)
Exportar datos en R
Una vez corregida la base de datos, es posible exportar la información para emplearla posteriormente en R o en otros programas. R posee diferentes librerías y funciones que permiten exportar bases de datos dependiendo de la extensión de interés. En la siguiente tabla se resume el origen, la extensión, la librería, y la función para cargar cada base de datos dependiendo de su extensión.
| Origen | Extensión | Librería | Función |
|---|---|---|---|
| Texto | .txt | utils* | write.table() |
| Texto | .csv (comas) | utils* | write.csv() |
| Texto | .csv (punto y coma) | utils* | write.csv2() |
| Excel | .xlsx | openxlsx | write.xlsx() |
| SPSS | .sav | haven | write_sav() |
| SAS | .sas7bdat | haven | write_sas() |
| STATA | .dta | haven | write_dta() |
Ejemplo exportar datos en R
Para mostrar el empleo de estas funciones, suponga que queremos exportar la base de datos en extensión, .xlsx. Para ello se emplea entonces la función write.xlsx() de la librería openxlsx.
library(openxlsx)
## Se escribe el nombre del archivo, junto a la extensión de donde se quiera
## guardar
write.xlsx(x = datos, "C:/Users/user/Desktop/datos.xlsx")
Referencias
Esquivel, E. (2016). La enseñanza de la estadı́stica y la probabilidad, más allá de procedimientos y técnicas. Cuadernos de Investigación y Formación En Educación Matemática, 21–31.
Recchioni, L. (2016). Evaluación de las polı́ticas públicas: Relevancia de la estadı́stica. Oikonomos, 1.